|
Introduction Previous Work Algorithm Experiment Conclusions References Report Authors: crh13 | rz33 |
Hand Gesture RecognitionEE 547: Computer Vision Poster ProjectRemik Ziemlinski Christopher HynesExperiment Sample data was taken with a digital camera, in front of a black cloth. Another black cloth was used as a sleeve to make the hand stand out. The idea was to make the key problem classification, not segmentation. The hand was the only object in the scene, and was always entirely in view. Pictures of a single (right) hand were taken in a variety of positions and orientations: x in a closed fist, x in an open palm, x pointing, and x grabbing. Noisy images were also taken, but it is apparent that they will fail in the segmentation phase, so they were disregarded. Since the emphasis of most research papers is on hand motion, many static facets had to be explored as "in the dark." The measurements that follow support some of the propositions made about invariant properties that help in feature extraction or classification. If the exposure of the arm is limited by a sleeve (dark), then compactness is a good estimate of what general state the hand is in. Thresholding at 25 is reasonable for roughly knowing whether a hand is Closed or Open (see below). This is important in making a decision on a hand gesture with the presence of a possible noisy pseudo-finger feature. Again, this is sensitive if arm exposure is great, so its feasibility is limited without correct and compact localization. We find that the moment method for calculating center of mass is not robust to the morphable model of the hand. Therefore a Euclidean distance transform was used. The actual implementation is very nearly a Medial Axis Transform. That is why in future improvements, this step will be incorporated to the skeletonizing phase. The present skeletonizing algorithm can be modified with clever labeling to track the notion of a timestamp. Regardless, the experimentation has shown us the sensibility of using a distance transform over the standard 1st order moment descriptor. 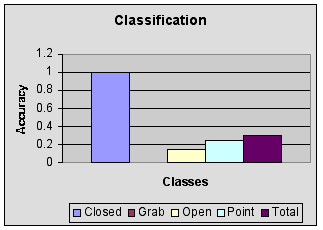
The plotted data above shows the ineffectiveness of the classifier. The class of images when restricted to the "Closed" shows perfect accuracy. This may be a result of the visual cues which is easier to partition from the others. The "Grab" class shows no accuracy since only 1 image was available that was representative. The total data set was made up of 23 images. This may be considered small, but due to the constraints of the static gesture domain and number of classes plausible it is not unreasonable. The last result to the right shows the accuracy on the entire set, which is about 33%. |